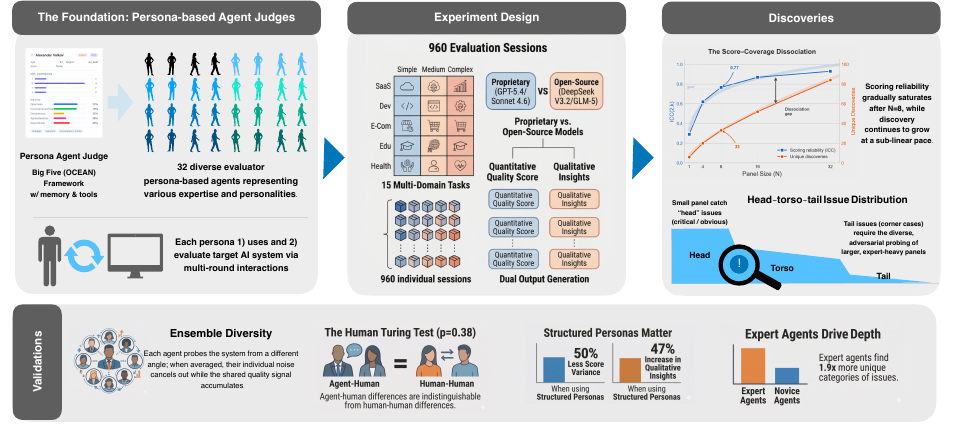
Primary Findings 2
Scores saturate fast. Discoveries keep growing.
The paper's central result is the split between measurement reliability and issue discovery coverage. The figure should be read as the evidence, not decoration.
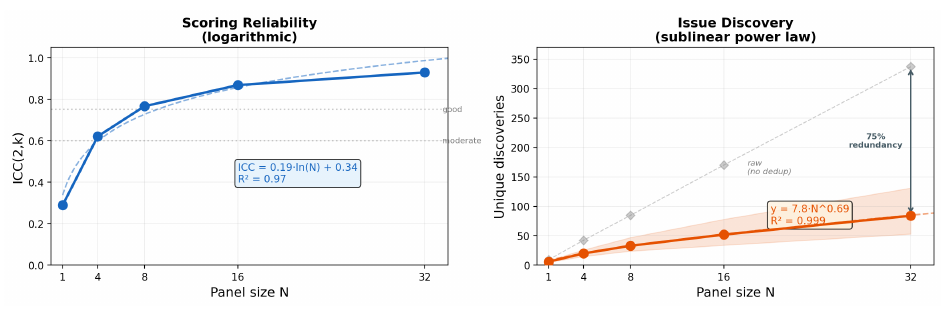
82%N=8 is already strong for score reliability.
42%N=8 is still thin for discovery coverage.
b=.69Unique issue discovery follows a power-law tail.power-law discovery curve exponent